〜研究内容〜
マルチエージェント強化学習を用いたニューラル機械翻訳の連携

概要
ニューラル機械翻訳(Neural Machine Translation,NMT)の誕生により近年,機械翻訳の精度がより一層高くなり,世間から大きな注目を集めている.このような高精度のニューラル機械翻訳を構築するためには,高品質の対訳データが大量に必要となる.従来,web上の大量の対訳データを集めることで,汎用的なニューラル機械翻訳が構築されてきた.このようなニューラル機械翻訳を特定のドメインに特化した高品質な対訳データで再学習することでカスタマイズが行われてきた.しかしながら,特定のドメインに特化した高品質な対訳データを一組織で構築するには膨大なコストがかかる.複数の組織が対訳データを共有するにも,著作権やセキュリティ等の問題で対訳データを共有することが難しい.
このような問題を解決するために,各自の持つデータを秘匿にしたまま,各データ所有者の下で学習したモデルを連携させる連合学習が用いられている.連合学習では,データではなく,各クライアントで構築されたモデルをサーバで集約して合成し,クライアントに分配する.クライアントでは,各自のデータを用いて,合成されたモデルを再学習し,再度サーバにモデルを送付する.このクライアントでの学習とサーバでの合成を繰り返すことで,全クライアントが協働でモデルを改善していくことができる.この連合学習により,ユーザ間での対訳データの共有が不要となり,組織内に蓄積された非公開の大量の対訳データの利用を促進することが期待されている.しかしながら,各データ所有者の持つデータの分布がそれぞれ異なっている場合,連合学習において非独立同一分布(Non-independent and identically distrib-uted (Non-iid))と呼び,モデルの精度低下に繋がるため,全ての翻訳モデルを統合することが,必ずしも全てのクライアントの翻訳モデルの精度向上に繋がるとは限らない.
そこで,私は連合学習において,集約プロセスのたびに動的に連携相手を選択し,翻訳モデルを統合するマルチエージェントシステムを提案し研究している.エージェントは各クライアントに配置され,報酬を最大化させる方策を獲得するために深層強化学習を用いる.
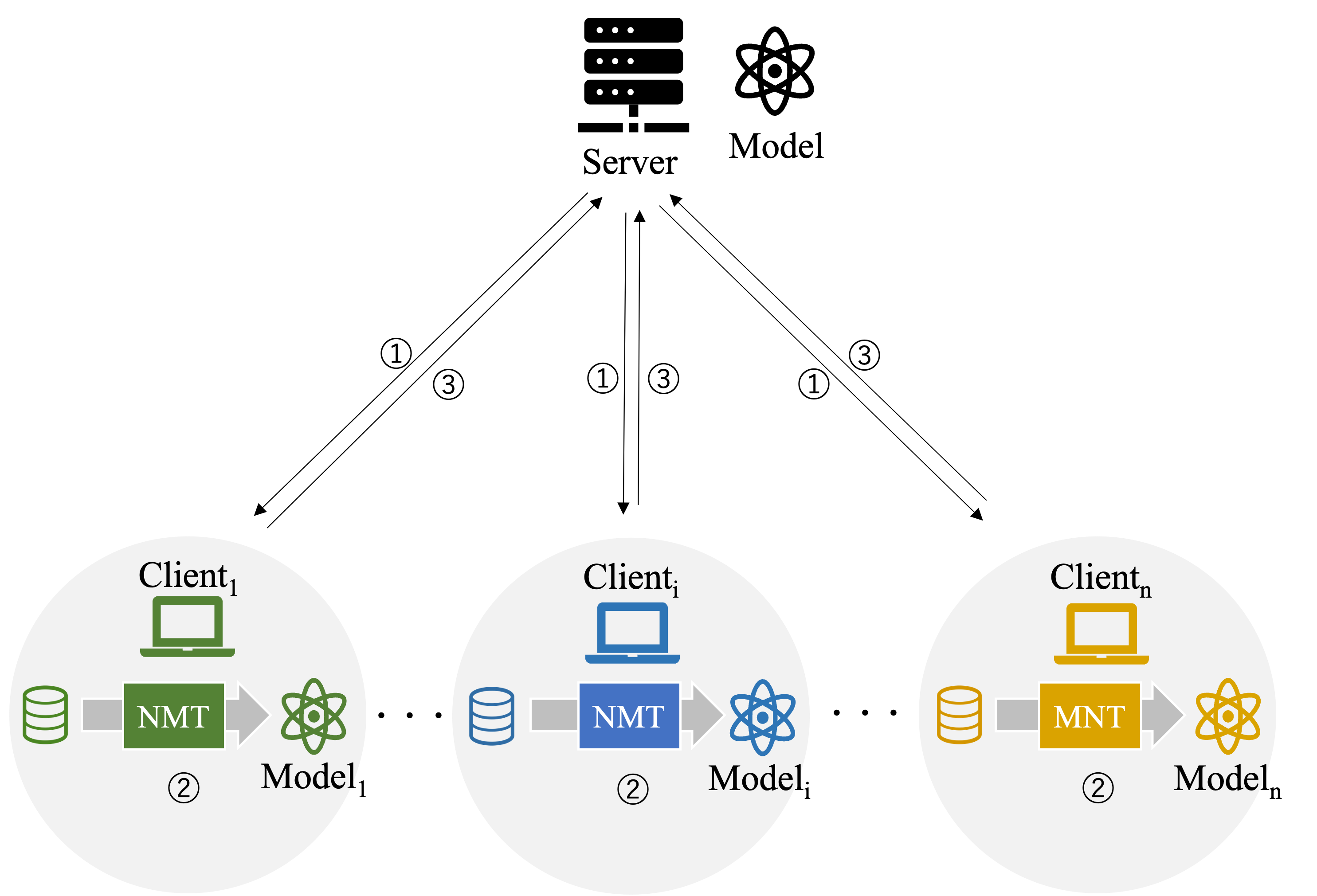
連合学習
連合学習(Federated Learning)は,2016年に提唱された分散型の機械学習手法である.連合学習では,参加する各組織が所有する学習データを共有せずに,機械学習モデルの学習に必要な情報だけをローカルで計算し共有する.つまり,各組織は自身のデータを保持しながら,学習モデルの学習に寄与し,複数の組織間での協力的な学習が実現される.一般的に連合学習は複数のクライアントと一つのサーバから構成され,以下のような流れで学習する.
まず,サーバはランダムに設定された初期モデルを生成する.次に,モデルを各クライアントに配布する(上図①).各クライアントは受信したモデルを使用して,ローカルで規定のステップのNMTの学習を行う(上図②).そして,各クライアントは学習を終えると,学習済みのモデルをサーバに送信する(上図③).受け取ったサーバは,モデルを集約する.その後①から③の動作を再び実行し,これを規定回数繰り返す.
マルチエージェント強化学習
強化学習とは,教師データを事前に与えられず,かつ観測可能な情報が行動によって変化する状況で,最適な行動の系列を見つけることを目指す機械学習の一種である.強化学習の一般的なケースは,自律的に動く主体が周囲に影響を与える場合であり,行動する主体をエージェント(Agent),影響を受ける対象を環境(Environment)と呼ぶ.エージェントが環境に対して行動することを行動(action)と呼び,エージェントの行動によって変化する環境の要素を状態(state)と呼ぶ.エージェントがどの行動を選択するかによってその後の状態が変わる.また,強化学習では,未知の環境でのエージェントの行動の良し悪しを評価する指標として報酬(reward)と呼ばれるスカラー値が利用されている.
実際の世界では,ある環境内に複数のエージェントが同時に存在することは一般的である.同じ環境で複数の強化学習のエージェントが同時に学習,行動し,お互いに影響し合う自律分散型システムをマルチエージェント強化学習(Multiagent reinforcement learning,MARL)と呼ぶ.マルチエージェント深層強化学習を用いることで,将来的なモデル精度の期待値を考慮し,最適な協調パートナーを選択することができる.
マルチエージェント強化学習の例としてサッカーの戦略がある.各プレイヤー(エージェント)は、味方との協力と敵との競争を通じて得点を目指す行動を学習する.各エージェントは環境の一部として作用し,他のエージェントの行動を観察,適応する.報酬はゴールを獲得すること,パスを成功させること,相手チームからボールを奪うことなど,サッカーの試合で望ましい結果をもたらす行動に設定される.これらの要素を組み合わせて,各エージェントは自身の役割に応じた最適な行動を選択できるように学習する.
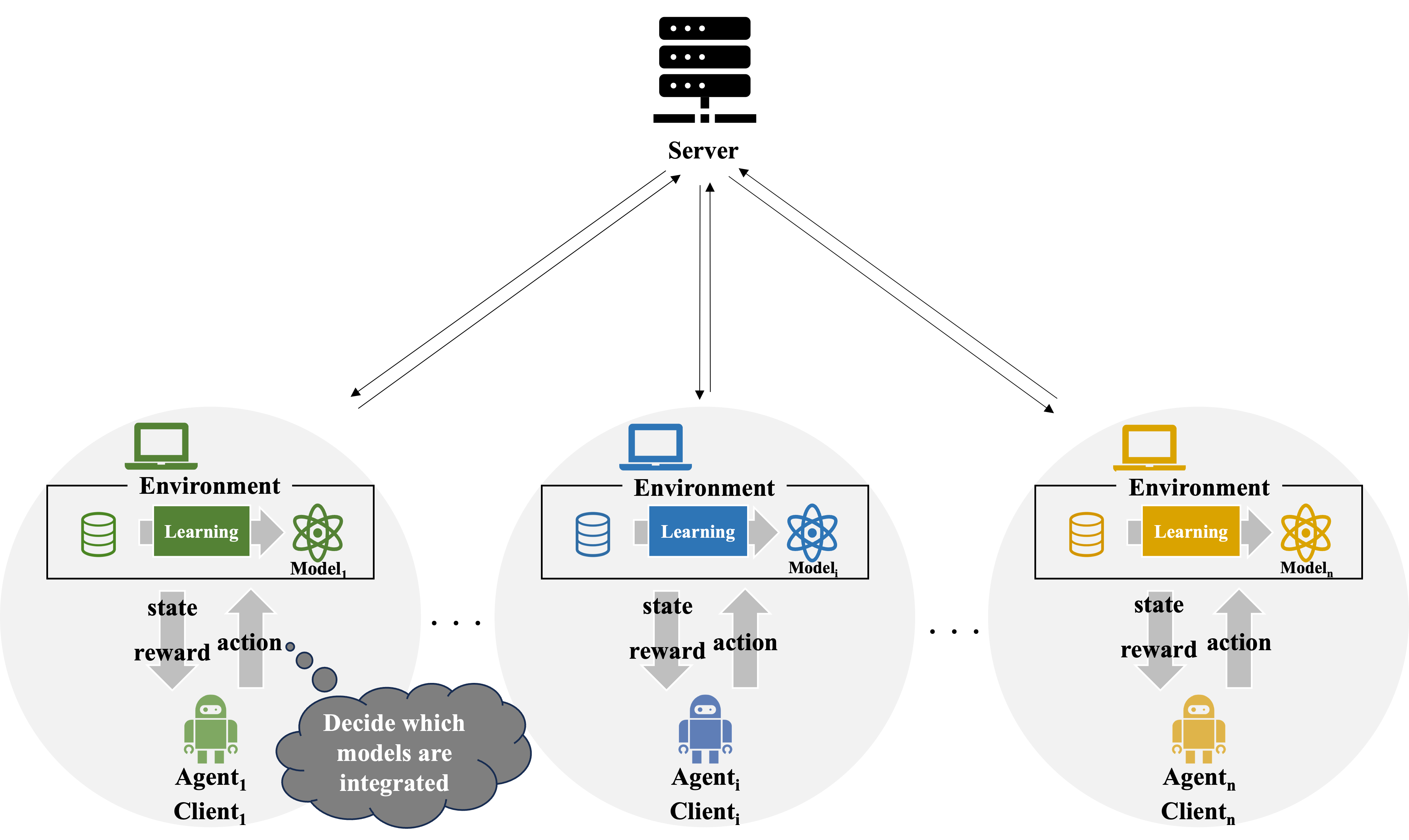
マルチエージェント強化学習を用いた連合学習
連合学習において各データ所有者の持つデータの分布がそれぞれ異なっている場合(Non-iid),モデルの精度低下に繋がり,全ての翻訳モデルを統合することが,必ずしも全てのクライアントの翻訳モデルの精度向上に繋がるとは限らない.そこで,連合学習にマルチエージェント強化学習を取り入れ,エージェントの学習によって最適な協調パートナーを選択できるようにする.各クライアントは各自の持つデータセットを用いてモデルを学習させ,そのモデルの状態と報酬をもとにどのモデルを集約するか(行動)を決定する.エージェントを各クライアントに配置し,得られる報酬を最大化させる方策を獲得する.